PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Por um escritor misterioso
Last updated 14 abril 2025
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://d3i71xaburhd42.cloudfront.net/38fb1902c6a2ab4f767d4532b28a92473ea737aa/5-Table1-1.png)
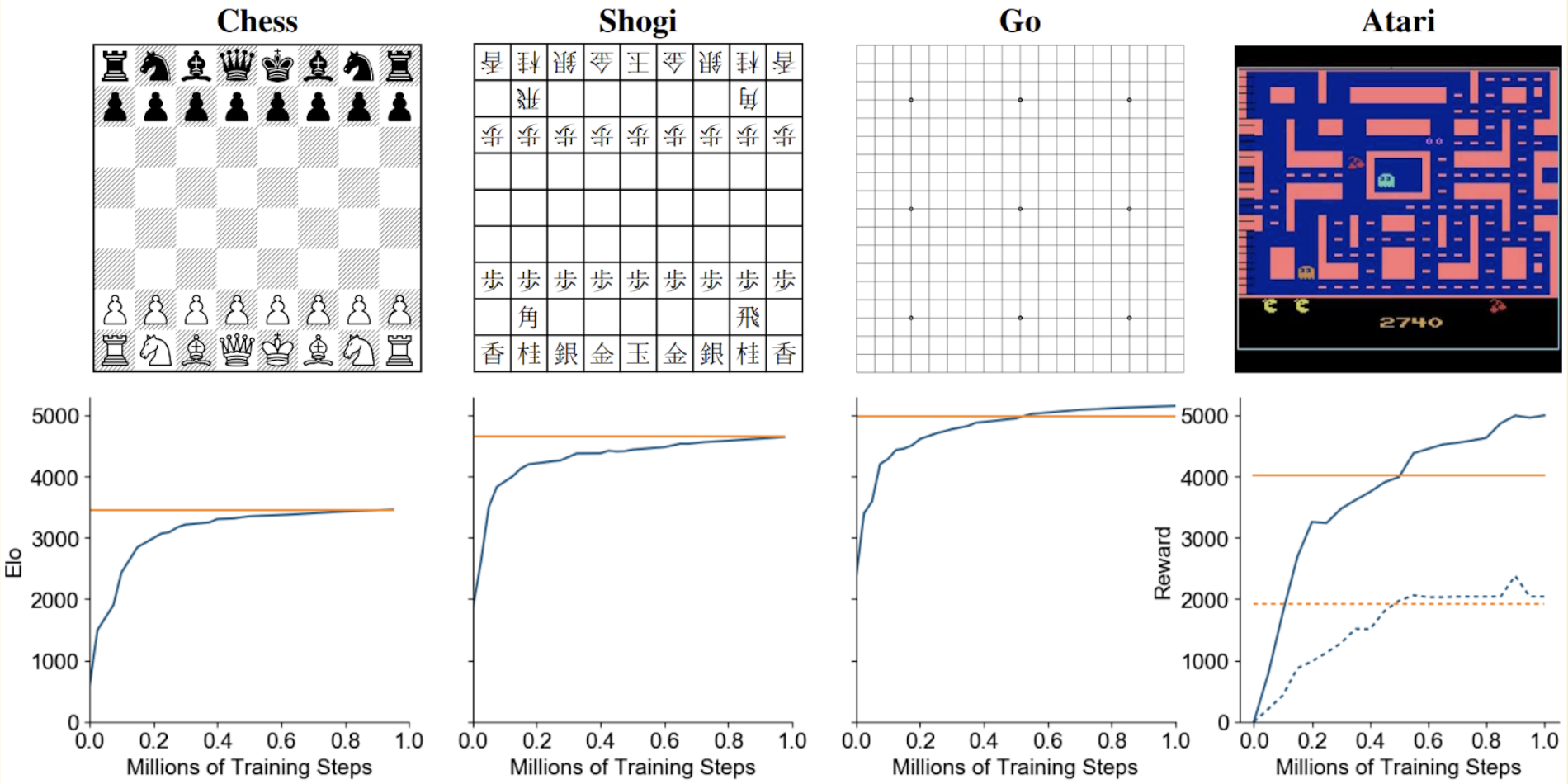
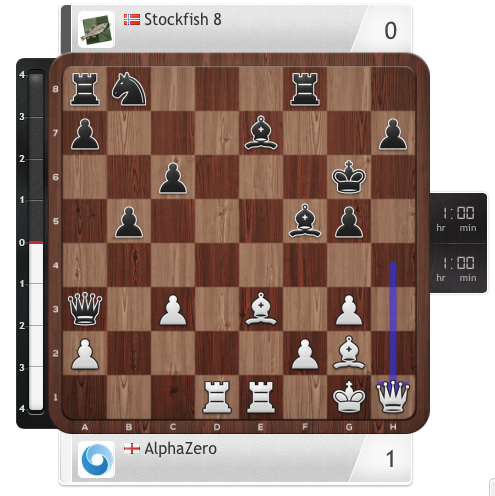
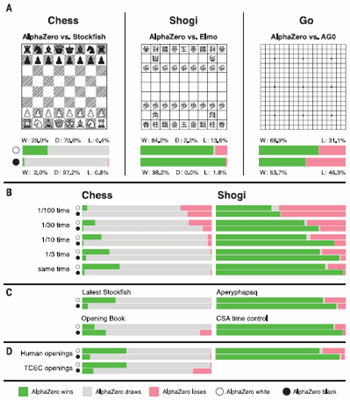
This paper generalises the approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains, and convincingly defeated a world-champion program in each case. The game of chess is the most widely-studied domain in the history of artificial intelligence. The strongest programs are based on a combination of sophisticated search techniques, domain-specific adaptations, and handcrafted evaluation functions that have been refined by human experts over several decades. In contrast, the AlphaGo Zero program recently achieved superhuman performance in the game of Go, by tabula rasa reinforcement learning from games of self-play. In this paper, we generalise this approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains. Starting from random play, and given no domain knowledge except the game rules, AlphaZero achieved within 24 hours a superhuman level of play in the games of chess and shogi (Japanese chess) as well as Go, and convincingly defeated a world-champion program in each case.
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://www.chessprogramming.org/images/thumb/f/f0/DeepLearning.jpg/300px-DeepLearning.jpg)
Deep Learning - Chessprogramming wiki
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://upload.wikimedia.org/wikipedia/commons/7/7b/RS_Chess_Computer.JPG)
Computer chess - Wikipedia
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://d3i71xaburhd42.cloudfront.net/071e11e5845e72466bb8fbdc617d45c4d83e7b0a/2-Figure1-1.png)
PDF] The Chess Transformer: Mastering Play using Generative Language Models
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://i.ytimg.com/vi/2ciR6rA85tg/maxresdefault.jpg)
AlphaZero: DeepMind's New Chess AI
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://pub.mdpi-res.com/electronics/electronics-10-01533/article_deploy/html/images/electronics-10-01533-g007.png?1624867156)
Electronics, Free Full-Text
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://d3i71xaburhd42.cloudfront.net/3b10fed9fb1dec020c82e22de599035ce7306896/4-Figure1-1.png)
PDF] Deep Pepper: Expert Iteration based Chess agent in the Reinforcement Learning Setting
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://user-images.githubusercontent.com/4205182/34333105-ada817c6-e8fe-11e7-8c01-5958aaf264c1.gif)
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://www.researchgate.net/profile/Timothy_Lillicrap/publication/321571298/figure/fig1/AS:568407281147904@1512530264876/Training-AlphaZero-for-700-000-steps-Elo-ratings-were-computed-from-evaluation-games_Q320.jpg)
PDF) Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://0.academia-photos.com/attachment_thumbnails/39125249/mini_magick20220630-5577-1p53cfk.png?1656584411)
PDF) A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://d3i71xaburhd42.cloudfront.net/071e11e5845e72466bb8fbdc617d45c4d83e7b0a/5-Figure2-1.png)
PDF] The Chess Transformer: Mastering Play using Generative Language Models
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://www.pnas.org/cms/10.1073/pnas.1909565116/asset/36c3f132-988e-4e0c-9f50-afb648ec7711/assets/pnas.1909565116.fp.png)
What does AI's success playing complex board games tell brain scientists?
Recomendado para você
-
 AlphaZero really is that good14 abril 2025
AlphaZero really is that good14 abril 2025 -
 AlphaZero - Notes on AI14 abril 2025
AlphaZero - Notes on AI14 abril 2025 -
 PDF) Alternative Loss Functions in AlphaZero-like Self-play14 abril 2025
PDF) Alternative Loss Functions in AlphaZero-like Self-play14 abril 2025 -
 The Data Problem III: Machine Learning Without Data - Synthesis AI14 abril 2025
The Data Problem III: Machine Learning Without Data - Synthesis AI14 abril 2025 -
 Is AlphaZero really a scientific breakthrough in AI?, by Jose Camacho Collados14 abril 2025
Is AlphaZero really a scientific breakthrough in AI?, by Jose Camacho Collados14 abril 2025 -
 Chess for All Ages: AlphaZero Match Conditions14 abril 2025
Chess for All Ages: AlphaZero Match Conditions14 abril 2025 -
 DeepMind's AlphaGo Zero and AlphaZero14 abril 2025
DeepMind's AlphaGo Zero and AlphaZero14 abril 2025 -
 How AlphaZero Works – Augmented Lawyer14 abril 2025
How AlphaZero Works – Augmented Lawyer14 abril 2025 -
AlphaZero: DeepMind's New Chess AI14 abril 2025
-
 Move over AlphaGo: AlphaZero taught itself to play three different games14 abril 2025
Move over AlphaGo: AlphaZero taught itself to play three different games14 abril 2025
você pode gostar
-
 Stream Book II - Blind Witch (The mimic theme) by Nav14 abril 2025
Stream Book II - Blind Witch (The mimic theme) by Nav14 abril 2025 -
/i.s3.glbimg.com/v1/AUTH_b0f0e84207c948ab8b8777be5a6a4395/internal_photos/bs/2023/o/f/3wZgmVRu6oEkKlNcU6wQ/missao-antena2.jpg) rs Gato Galáctico e Luluca estreiam como dubladores no cinema14 abril 2025
rs Gato Galáctico e Luluca estreiam como dubladores no cinema14 abril 2025 -
 Prime Video Streaming libera função para assistir filmes e séries online com amigos – Meleka Pop14 abril 2025
Prime Video Streaming libera função para assistir filmes e séries online com amigos – Meleka Pop14 abril 2025 -
 Attack on Titan14 abril 2025
Attack on Titan14 abril 2025 -
 CAMPEONATO MUNDIAL DE VÔLEI MASCULINO: conheça o grupo do BRASIL e veja a tabela com os horários dos jogos14 abril 2025
CAMPEONATO MUNDIAL DE VÔLEI MASCULINO: conheça o grupo do BRASIL e veja a tabela com os horários dos jogos14 abril 2025 -
![Ônibus ETS 2: Caio Apache Vip IV Multi-Chassis v2.4 [V 1.45.x]](https://busroadmods.files.wordpress.com/2022/08/caio-apache-vip-iv-multi-chassis-v2.4-ets2-v-1-45-x-001.jpg?w=1366&h=768&crop=1) Ônibus ETS 2: Caio Apache Vip IV Multi-Chassis v2.4 [V 1.45.x]14 abril 2025
Ônibus ETS 2: Caio Apache Vip IV Multi-Chassis v2.4 [V 1.45.x]14 abril 2025 -
 Adesivo da Dama e o Vagabundo 0662 – Loja de adesivos14 abril 2025
Adesivo da Dama e o Vagabundo 0662 – Loja de adesivos14 abril 2025 -
 Radical red Easy randomizer nuzlocke - Lets Plays/Videos - The Pokemon Insurgence Forums14 abril 2025
Radical red Easy randomizer nuzlocke - Lets Plays/Videos - The Pokemon Insurgence Forums14 abril 2025 -
Naruto Shippuden Anime Kakashi Cosplay Youth Boys Cosplay Graphic Tshirt-xl : Target14 abril 2025
-
 Garten of BanBan tshirt design SVG/PNG/pdf/jpeg Garden of BanBan NabNab/ cutting File, grouped by colors,easy to use,Vector, Garten Birthday14 abril 2025
Garten of BanBan tshirt design SVG/PNG/pdf/jpeg Garden of BanBan NabNab/ cutting File, grouped by colors,easy to use,Vector, Garten Birthday14 abril 2025
