Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self-play
Por um escritor misterioso
Last updated 22 abril 2025
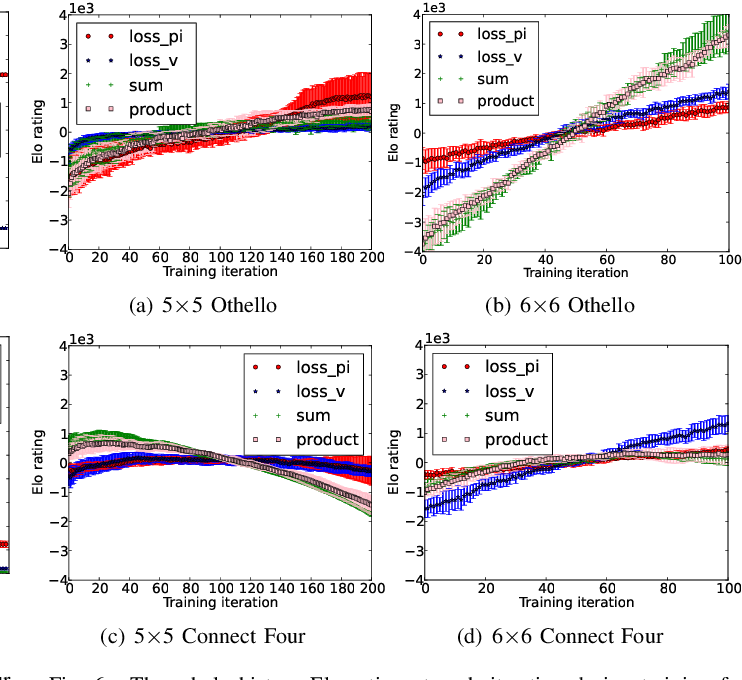
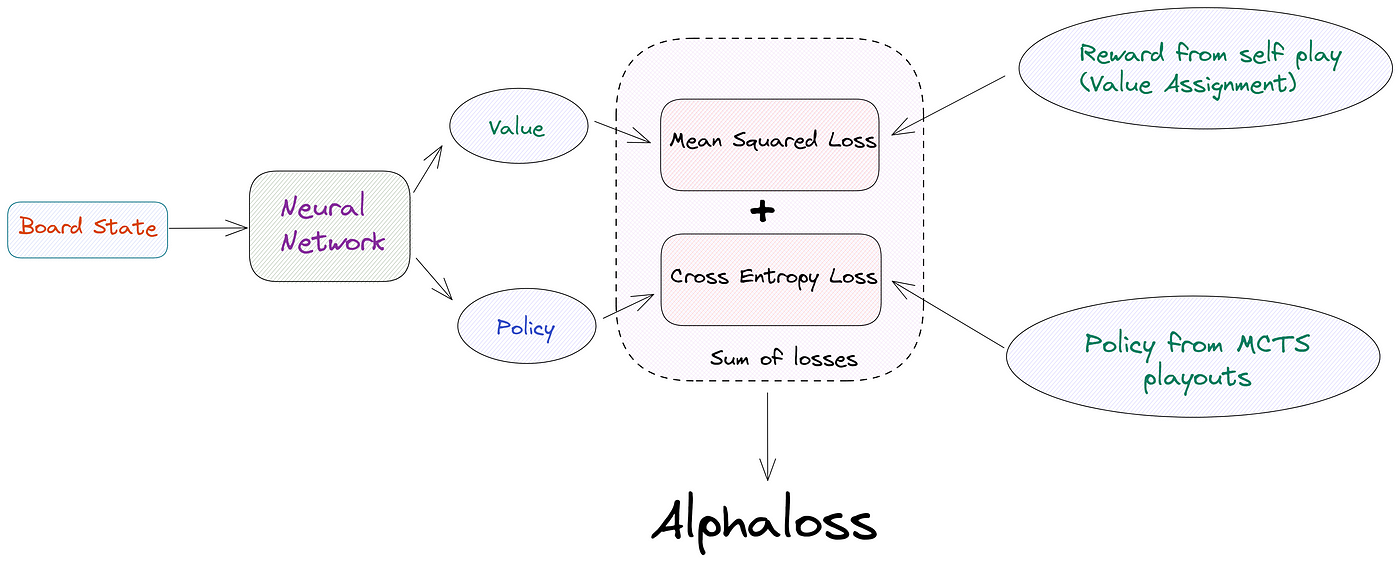
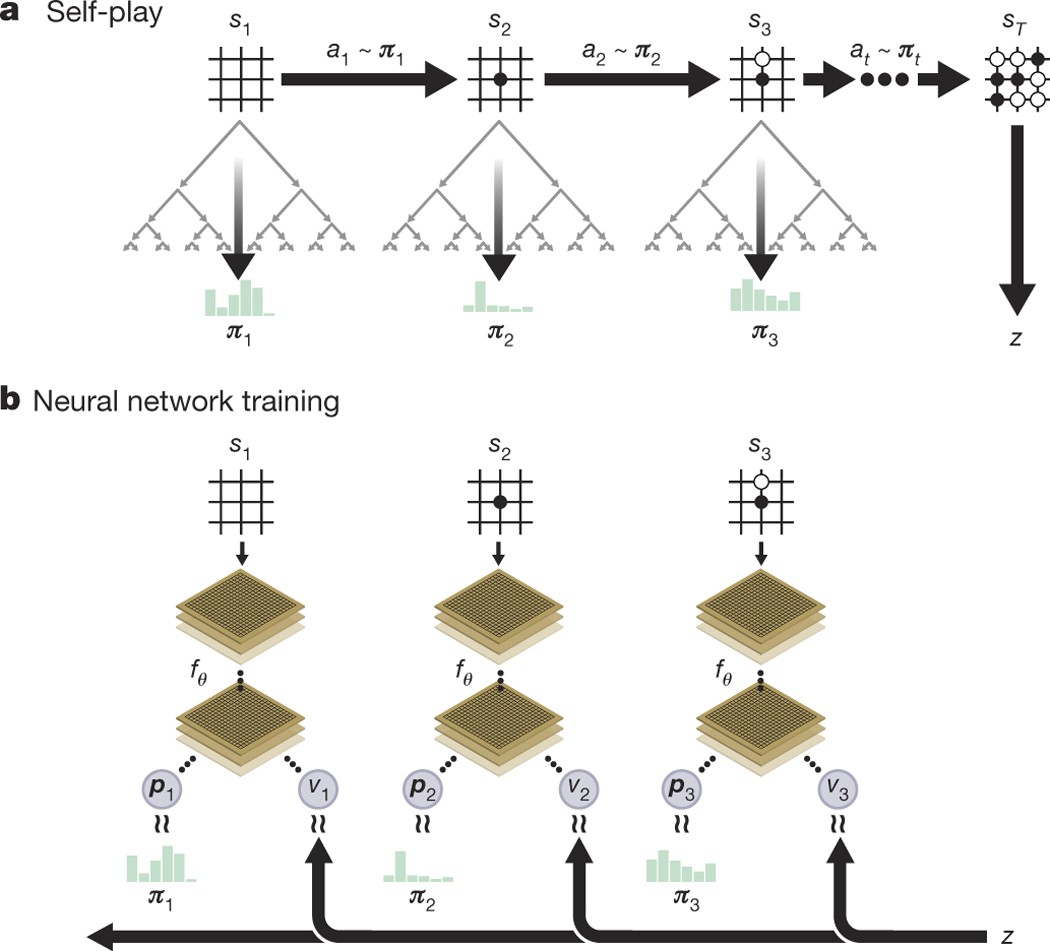
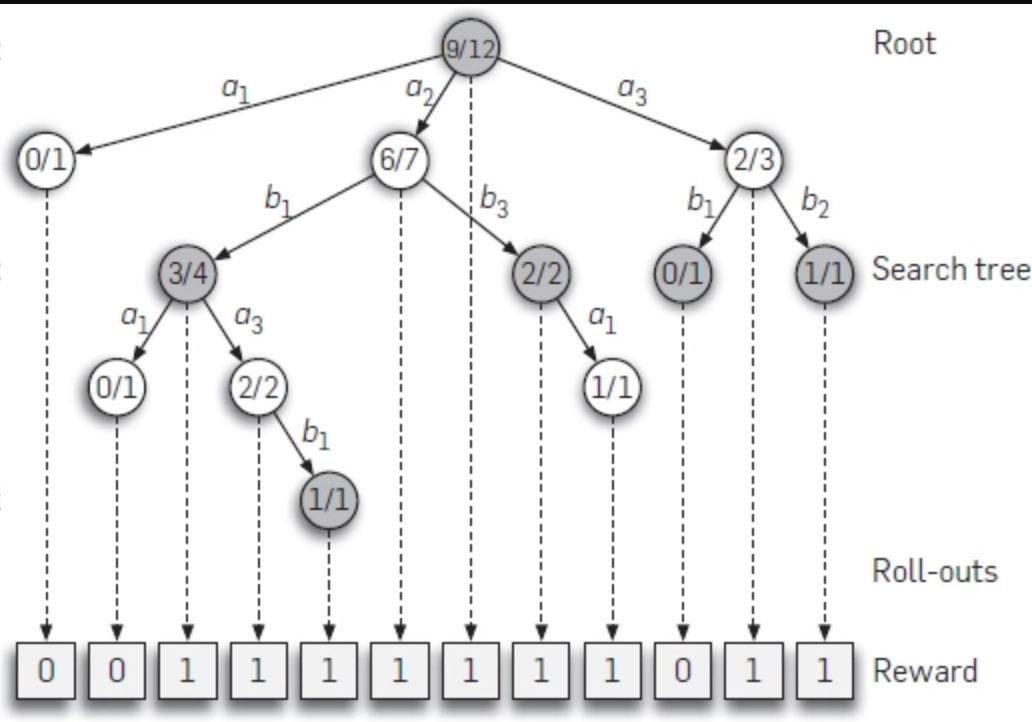
Results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Recently, AlphaZero has achieved outstanding performance in playing Go, Chess, and Shogi. Players in AlphaZero consist of a combination of Monte Carlo Tree Search and a Deep Q-network, that is trained using self-play. The unified Deep Q-network has a policy-head and a value-head. In AlphaZero, during training, the optimization minimizes the sum of the policy loss and the value loss. However, it is not clear if and under which circumstances other formulations of the objective function are better. Therefore, in this paper, we perform experiments with combinations of these two optimization targets. Self-play is a computationally intensive method. By using small games, we are able to perform multiple test cases. We use a light-weight open source reimplementation of AlphaZero on two different games. We investigate optimizing the two targets independently, and also try different combinations (sum and product). Our results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Moreover, we find that care must be taken in computing the playing strength. Tournament Elo ratings differ from training Elo ratings—training Elo ratings, though cheap to compute and frequently reported, can be misleading and may lead to bias. It is currently not clear how these results transfer to more complex games and if there is a phase transition between our setting and the AlphaZero application to Go where the sum is seemingly the better choice.

Strength and accuracy of policy and value networks. a Plot showing
AlphaZero from scratch in PyTorch for the game of Chain Reaction

LightZero: A Unified Benchmark for Monte Carlo Tree Search in

The future is here – AlphaZero learns chess

AlphaZero
Mastering the game of Go without human knowledge
AlphaZero Explained · On AI
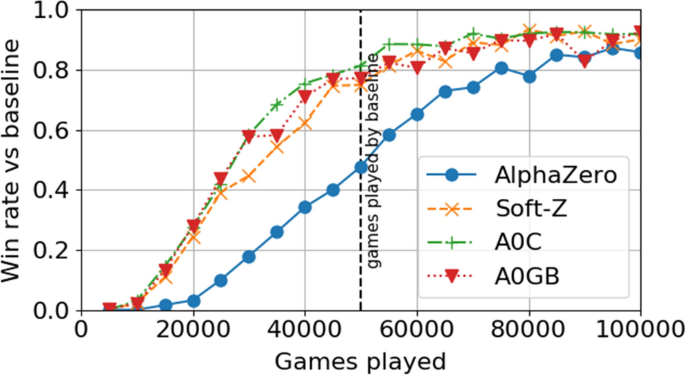
Value targets in off-policy AlphaZero: a new greedy backup
AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript

Why Artificial Intelligence Like AlphaZero Has Trouble With the
Recomendado para você
-
 AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours22 abril 2025
AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours22 abril 2025 -
 Stockfish (chess) - Wikipedia22 abril 2025
Stockfish (chess) - Wikipedia22 abril 2025 -
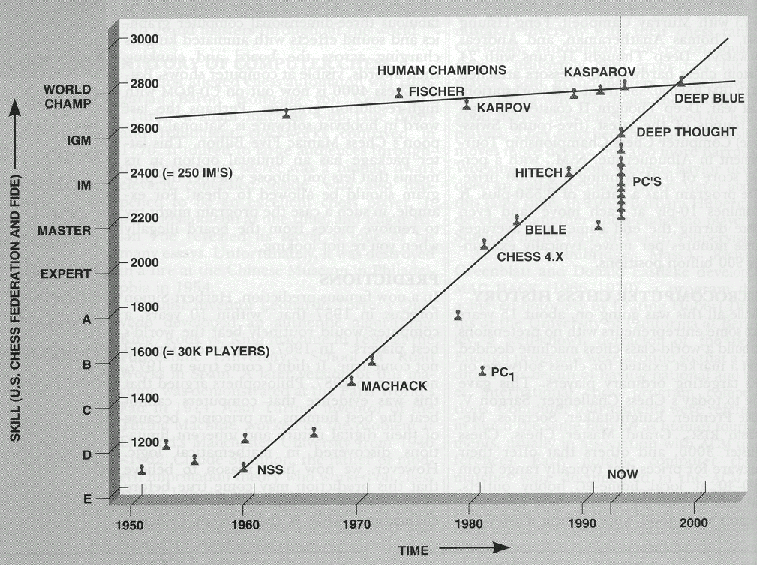 Time for AI to cross the human performance range in chess – AI Impacts22 abril 2025
Time for AI to cross the human performance range in chess – AI Impacts22 abril 2025 -
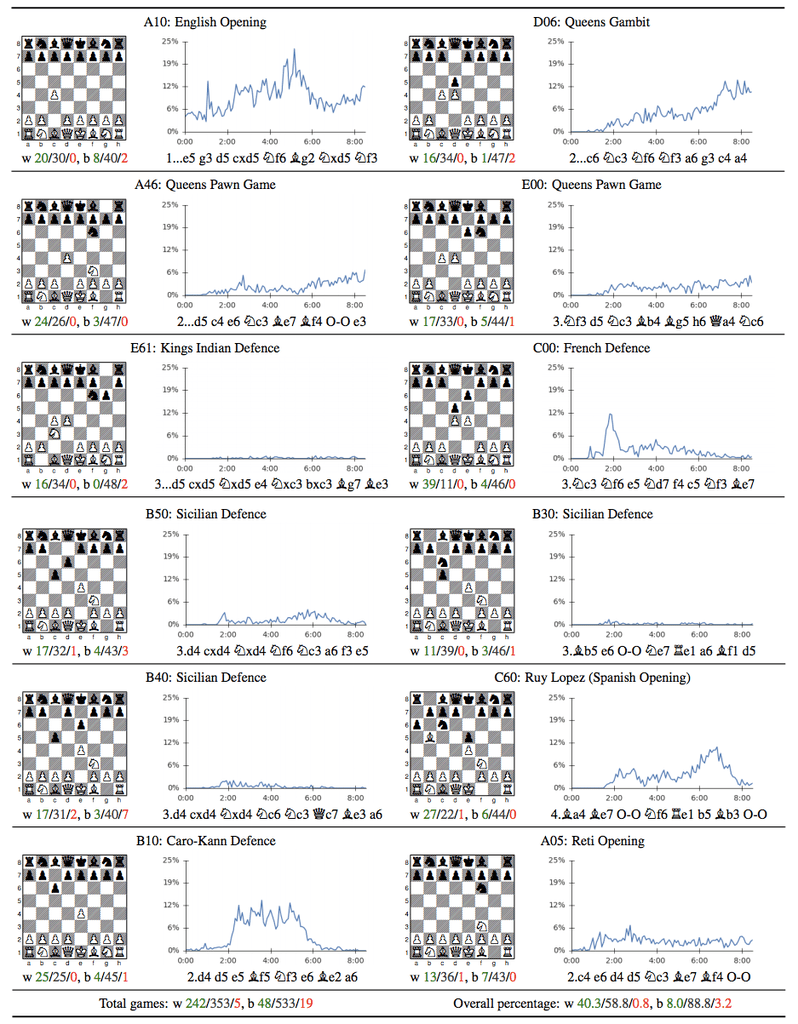 Google's AlphaZero Destroys Stockfish In 100-Game Match22 abril 2025
Google's AlphaZero Destroys Stockfish In 100-Game Match22 abril 2025 -
 New AlphaZero (4050 Elo) Played Perfect Chess Against Stockfish 15.1, Gothamchess, AlphaZero22 abril 2025
New AlphaZero (4050 Elo) Played Perfect Chess Against Stockfish 15.1, Gothamchess, AlphaZero22 abril 2025 -
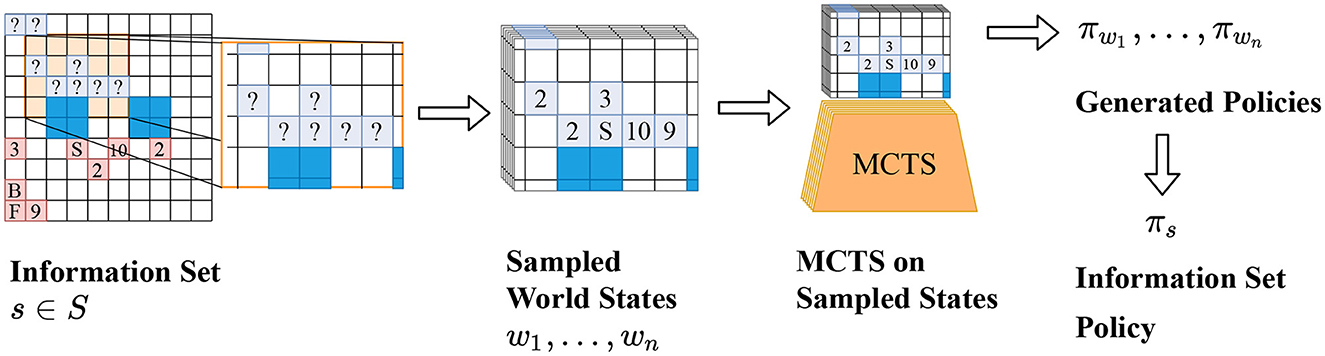 Frontiers AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong22 abril 2025
Frontiers AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong22 abril 2025 -
 ELO Ratings Benchmark (Game of Shogi)22 abril 2025
ELO Ratings Benchmark (Game of Shogi)22 abril 2025 -
 4050 Elo Rating Performance of AlphaZero, AlphaZero Vs AlphaZero, Chess com, Gotham chess22 abril 2025
4050 Elo Rating Performance of AlphaZero, AlphaZero Vs AlphaZero, Chess com, Gotham chess22 abril 2025 -
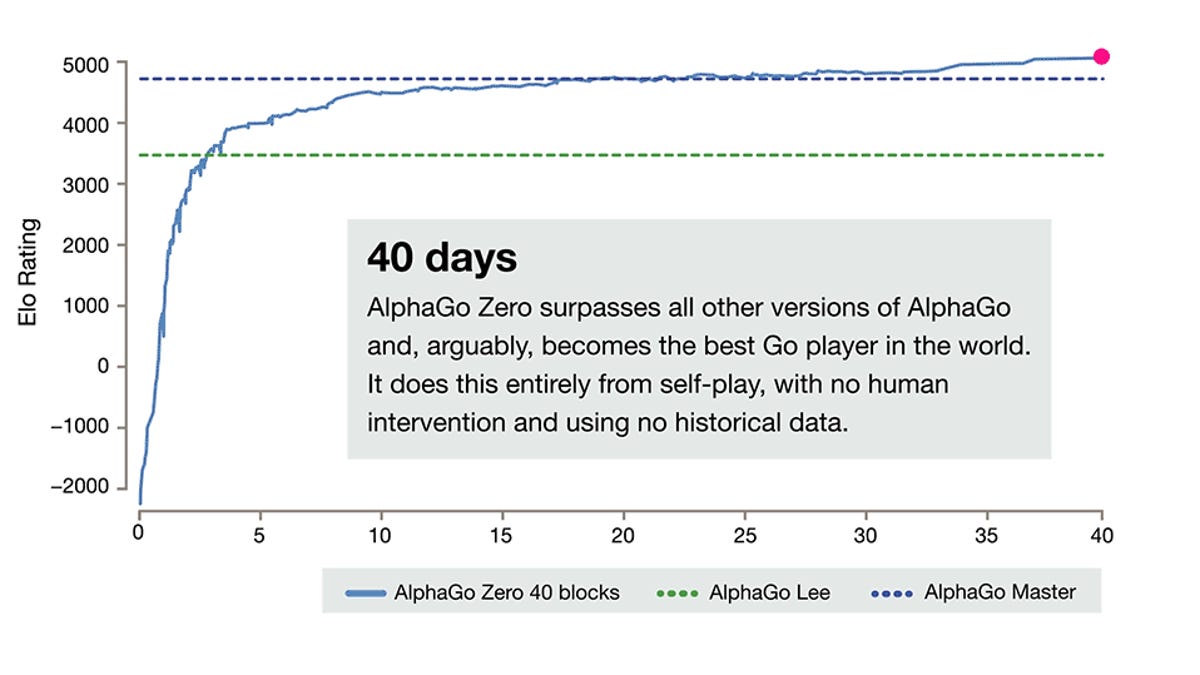 DeepMind AlphaGo Zero learns on its own without meatbag intervention22 abril 2025
DeepMind AlphaGo Zero learns on its own without meatbag intervention22 abril 2025 -
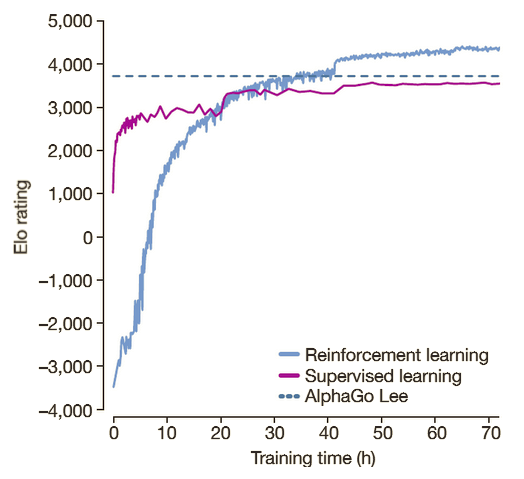 AlphaGo Zero Explained22 abril 2025
AlphaGo Zero Explained22 abril 2025
você pode gostar
-
 Jogo Educativo Ação Brincadeira Infantil Divertida Criança22 abril 2025
Jogo Educativo Ação Brincadeira Infantil Divertida Criança22 abril 2025 -
![Tough Man Mod apk [Remove ads][Unlimited money] download - Tough Man MOD apk 1.30 free for Android.](https://i.git99.com/upload/android/icon/2023/11/01/8e35c3e2e4c2d456f247bb0440fcbff6.jpg) Tough Man Mod apk [Remove ads][Unlimited money] download - Tough Man MOD apk 1.30 free for Android.22 abril 2025
Tough Man Mod apk [Remove ads][Unlimited money] download - Tough Man MOD apk 1.30 free for Android.22 abril 2025 -
 Estádios novos do FIFA 1822 abril 2025
Estádios novos do FIFA 1822 abril 2025 -
 Infinite Dendrogram Novel Volume 1322 abril 2025
Infinite Dendrogram Novel Volume 1322 abril 2025 -
 Ajuda para DESBLOQUEAR 3DS : r/gamesEcultura22 abril 2025
Ajuda para DESBLOQUEAR 3DS : r/gamesEcultura22 abril 2025 -
 Gvavaya Cosplay Anime Cyberpunk Edgerunners David Martinez Cosplay Cos22 abril 2025
Gvavaya Cosplay Anime Cyberpunk Edgerunners David Martinez Cosplay Cos22 abril 2025 -
 Cloud Gaming Reaches New Heights: Xbox Games Debut on Boosteroid in June22 abril 2025
Cloud Gaming Reaches New Heights: Xbox Games Debut on Boosteroid in June22 abril 2025 -
 Edward Newgate Murakumogiri Guandao Blade and Stand Building Blocks22 abril 2025
Edward Newgate Murakumogiri Guandao Blade and Stand Building Blocks22 abril 2025 -
 Tears For Fears - Everybody Wants To Rule The World (Official Archive Video)22 abril 2025
Tears For Fears - Everybody Wants To Rule The World (Official Archive Video)22 abril 2025 -
 Warrior Cat Designs22 abril 2025
Warrior Cat Designs22 abril 2025